Transformer
Transformer are [deep learning](deep learning.md) architectures mainly used for NLP, LLMs and other [generative AI](generative AI.md) tasks (e.g. image, sound, etc).
How does it work
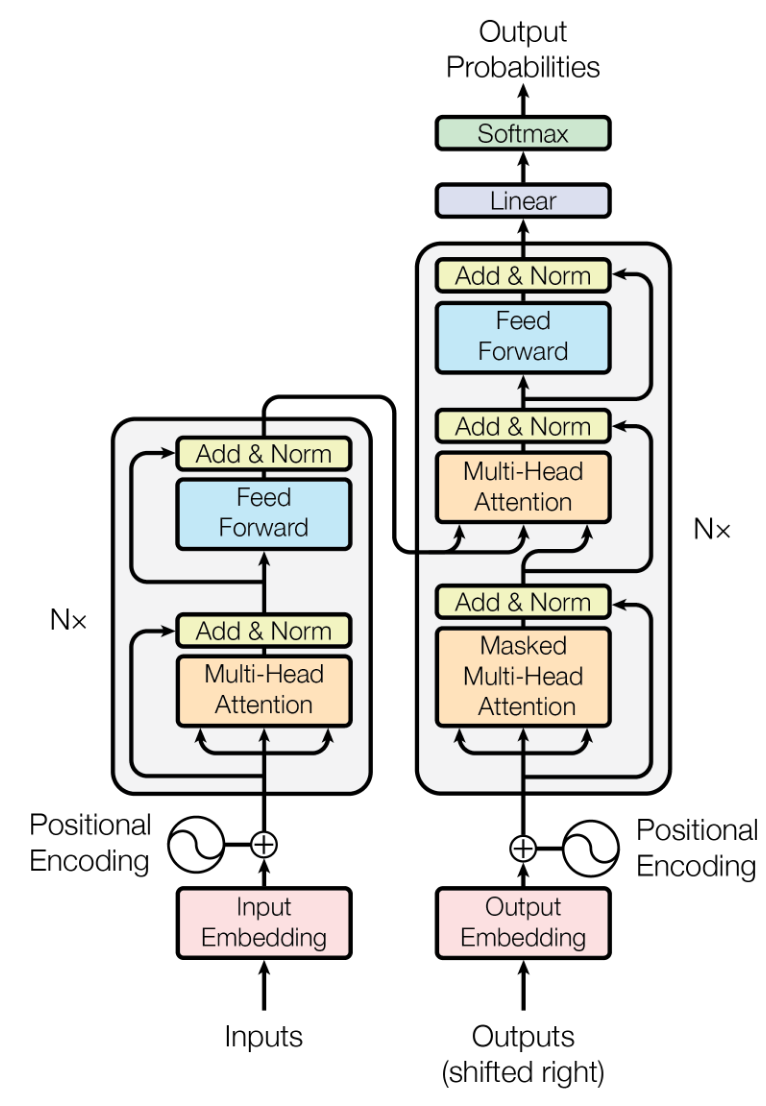
Transformer is based on a self-attention mechanism to avoid the need to process the data sequentially. It is composed of the 2 main parts:
- Encoder: takes the input and generate a hidden vectorial representation
- Decoder: use the hidden representation and generate output sequence
Each layer has:
- Multi-head attention: learns to assign weights to token according their relevance
- Feed-forward: applies a fully connected neural network to each position in the sequence independently. It ensures that local and global information are both utilized effectively for downstream tasks.
Autoregression
An [autoregressive model](autoregressive model.md) will apply regression (i.e. generate output according to inputs) based on its own previous generated output.
Models
GPT
[Generative pre-trained transformer](Generative pre-trained transformer.md) (GPT) is a dominant architecture choice for a lot of LLMs.
Resources
Papers
- arXiv:1706.03762 – Attention is all your need
- arXiv:2305.10435 – Generative Pre-trained Transformer: A Comprehensive Review